Implementation and interface¶
The typical step-by-step procedure to parametrize and run a DispaSET simulation is the following:
- Fill the Dispa-SET database with properly formatted data (time series, power plant data, etc.)
- Configure the simulation parameters (rolling horizon, data slicing) in the configuration file.
- Generate the simulation environment which comprises the inputs of the optimisation
- Open the GAMS simulation files (project: UCM.gpr and model: UCM_h.gms) and run the model.
- Read and display the simulation results.
This section provides a detailed description of these steps and the corresponding data entities.
Resolution Flow Chart¶
The whole resolution process for a dispa-SET run is defined from the processing and formatting of the raw data to the generation of aggregated result plots and statistics. A flow chart of the consecutive data entities and processing steps is provided hereunder.
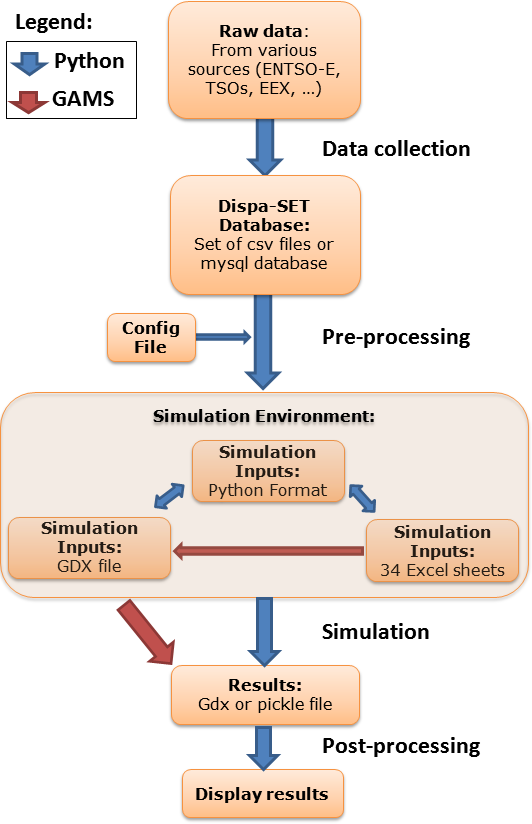
Each box in the flow chart corresponds to one data entity. The links between these data entities correspond to script written in Python or in GAMS. The different steps perform various tasks, which can be summarized by:
- Data collection:
- Read csv sheets, assemble data
- Convert to the right format (timestep, units, etc).
- Define proper time index (duplicates not allowed)
- Connect to database
- Check if data present & write data
- Write metadata
- Pre-processing:
- Read the config file
- Slice the data to the required time range
- Deal with missing data
- Check data for consistency (min up/down times, startup times, etc.)
- Calculate variable cost for each unit
- Cluster units
- Define scenario according to user inputs (curtailment, participation to reserve, amount of VRE, amount of storage, …)
- Define initial state (basic merit-order dispatch)
- Write the simulation environment to a user-defined folder
- Simulation environment and interoperability:
- Self-consistent folder with all required files to run the simulation:
- Excel files
- GDX file
- Input files in pickle format
- Gams model files
Python scripts to translate the data between one format to the other.
Possibility to modify the inputs manually and re-generate a GDX file from the excel files
- Simulation:
- The GAMS simulation file is run from the simulation environment folder
- Alternatively the model is run with the PYOMO solver
- All results and inputs are saved within the simulation environment
- Post-processing:
- Reads the simulation results saved in the simulation environment
- Aggregates the power generation and storage curves
- Computates of yearly statistics
- Generates plots
Dispa-SET database¶
Although two versions of the database are available (mysql and csv), the public version of Dispa-SET only comes with the latter. The Dispa-SET input data is stored as csv file in directory structure. A link to the required data is then provided by the user in the configuration file.
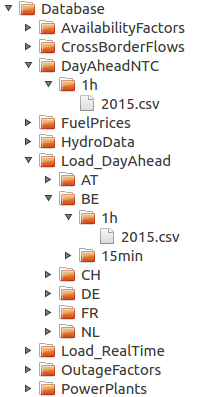
The above figure shows a partially unfolded view of the database structure. In that example, data is provided for the day-ahead net transfer capacities for all lines in the EU, for the year 2015 and with a 1h time resolution. Time series are also provided for the day-ahead load forecast for Belgium in 2015 with 1h time resolution.
Configuration File¶
The excel config file is read at the beginning of the pre-processing phase. It provides general inputs for the simulation as well as links to the relevant data files in the database.
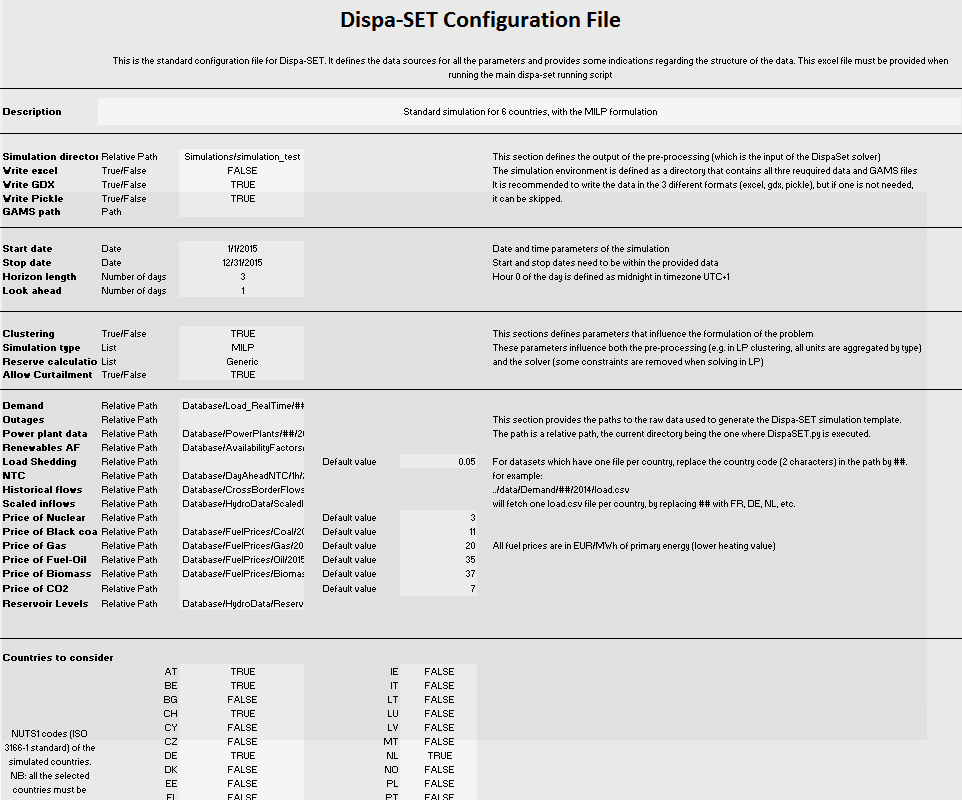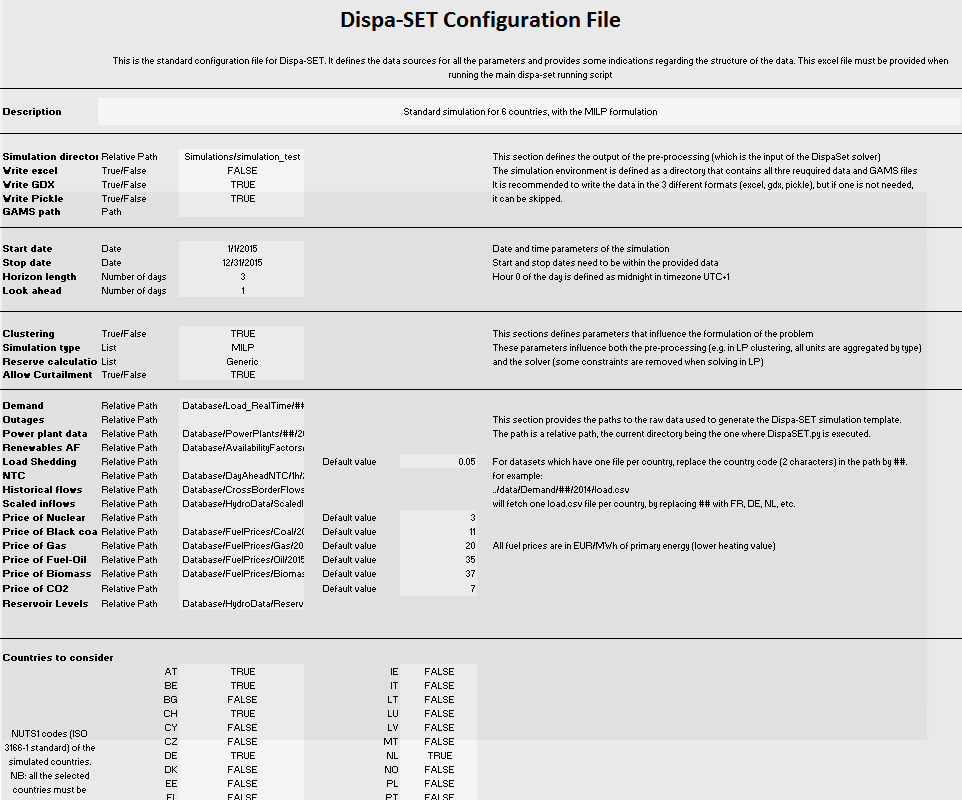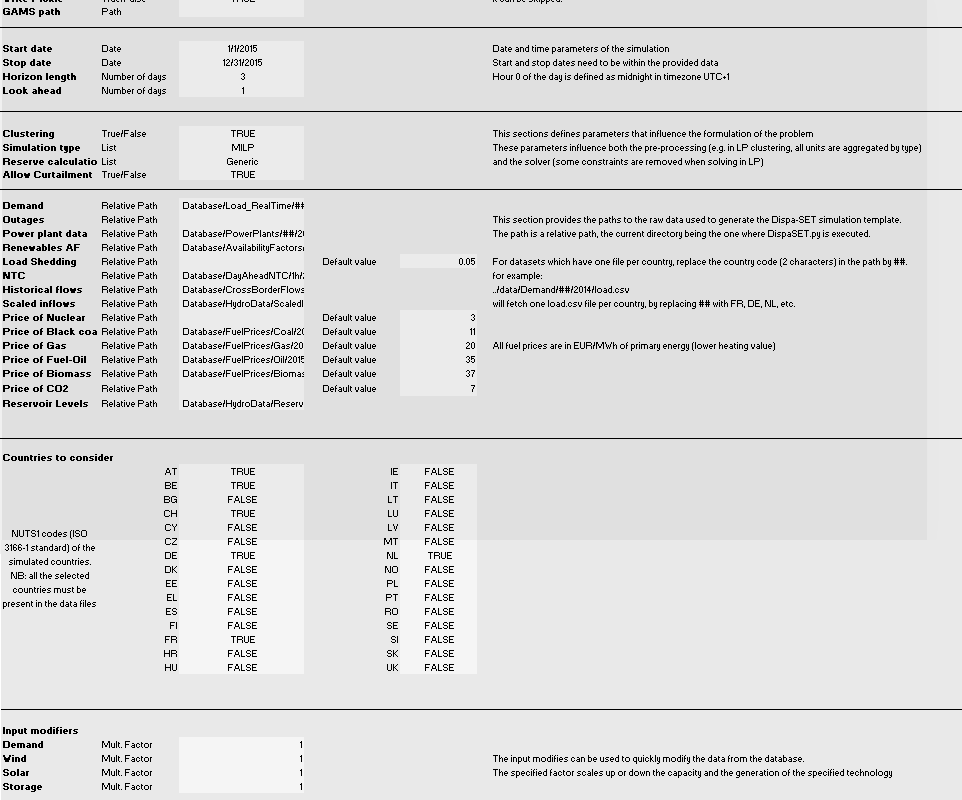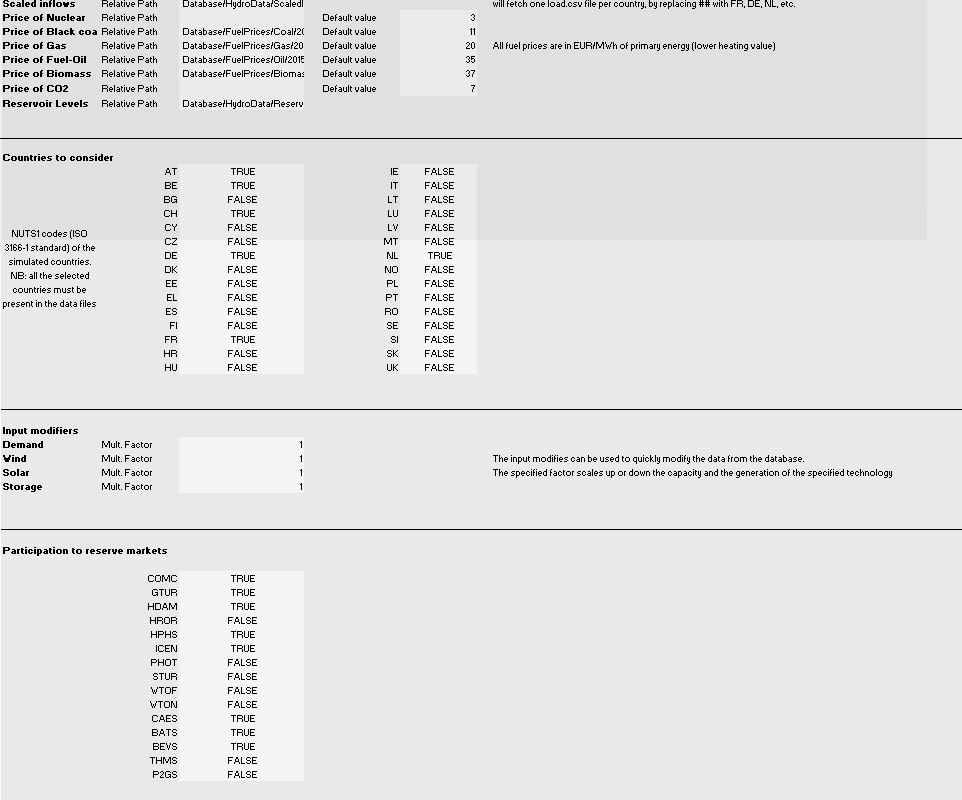
Simulation environment¶
This section describes the different simulation files, templates and scripts required to run the DispaSET model. For each simulation, these files are included into a single directory corresponding to a self-sufficient simulation environment.
A more comprehensive description of the files included in the simulation environment directory is provided hereunder.
UCM_h.gms and UCM.gpr¶
UCM_h.gms is the main GAMS model described in Chapter 1. A copy of this file is included in each simulation environment, allowing keeping track of the exact version of the model used for the simulation. The model must be run in GAMS and requires a proper input file (Inputs.gdx).
| Requires: | Inputs.gdx | Input file for the simulation. |
| Generates: | Results.gdx | Simulation results in gdx format |
| . | Results.xlsx | Simulation results in xlsx format. |
UCM.gpr is the GAMS project file which should be opened before UCM_h.gms.
make_gdx.gms¶
GAMS file that reads the different template excel files and generates the Inputs.gdx file. This file should be opened in GAMS.
| Requires: | InputDispa-SET – xxx.xlsx | DispaSET template files |
| Generates: | Inputs.gdx | Input file for the simulation |
makeGDX.bat¶
Batch script that generates the input file from the template without requiring opening GAMS. The first time it is executed, the path of the GAMS folder must be provided.
| Requires: | InputDispa-SET – xxx.xlsx | DispaSET template files |
| . | make_gdx.gms | GAMS file to generate Inputs.gdx |
| Generates: | Inputs.gdx | Input file for the simulation |
writeresults.gms¶
GAMS file to generate the excel Results.xlsx file from the Results.gdx generated by GAMS (in case the write_excel function was deactivated in GAMS.
| Requires: | Results.gdx | Simulation results in gdx format |
| Generates: | Results.xlsx | Simulation results in xlsx format |
Inputs.gdx¶
All the inputs of the model must be stored in the Inputs.gdx file since it is the only file read by the main GAMS model. This file is generated from the DispaSET template.
| Requires: | InputDispa-SET – xxx.xlsx | DispaSET template files |
| Generates: |
InputDispa-SET - [ParameterName].xlsx¶
Series of 42 excel files, each corresponding to a parameter of the DispaSET model (see Chapter 1). The files must be formatted according to section 2.2.
InputDispa-SET - Sets.xlsx¶
Single excel file that contains all the sets used in the model in a column format.
InputDispa-SET - Config.xlsx¶
Single excel file that contains simulation metadata in the form of a Table. This metadata allows setting the rolling horizon parameter and slicing the input data to simulate a subset only.
| FirstDay | 2012 | 10 | 1 | First day of the simulation in the template data |
| LastDay | 2013 | 9 | 30 | Last day of the simulation in the template data |
| RollingHorizon Length | 0 | 0 | 3 | Length of the rolling horizons |
| RollingHorizon LookAhead | 0 | 0 | 1 | Overlap period of the rolling horizon |
Structure of the Excel template¶
The name of the input files are “Input Dispa-SET – [Parameter name].xlsx”. These files contain the data to be read by the model, after conversion into a GDX file.
The structure of all input files follows the following rules:
There is one file per model parameter
Each file contains only one sheet
The first row is left blank for non-time series data (i.e. data starts at A2)
- For time series data, the rows are organized as follows:
- The first row is left blank
- Rows 2 to 5 contains the year, month, day and hour of each data
- Row 6 contains the time index of the data, which will be used in DispaSET
- The data therefore starts at A6
If one of the input sets of the data is u (the unit name), it is always defined as the first column of the data (column A)
If one of the input sets of the data is h (the time index), it is always defined as the only horizontal input in row 6
In the case of the file “Input Dispa-SET – Sets.xlsx”, all the required sets are written in columns with the set name in row 2.
Post-processing¶
Post-processing is implemented in the form of a series of functions to read the simulation inputs and results, to plot them, and to derive statistics.
The following values are computed:
- The total energy generated by each fuel, in each country.
- The total energy curtailed
- the total load shedding
- The overall country balance of the interconnection flows
- The total hours of congestion in each interconnection line
- The total amount of lost load, indicating (if not null) that the unit commitment problem was unfeasible at some hours
- The number of start-ups of power plants for each fuel
The following plots can be genrated:
- A dispatch plot (by fuel type) for each country
- A commitment status (ON/OFF) plot for all the unit in a given country
- The level (or state of charge) of all the storage units in a given country
- The overall power generation by fuel type for all countries (bar plot)
An example usage of these funciones is provided in the “Read_Results.ipynb” notebook.